(1.廣州大學(xué)機械與電氣工程學(xué)院,廣東 廣州 510006;2.廣東工業(yè)大學(xué)智能檢測與制造物聯(lián)教育部重點實驗室,廣東 廣州 510006;3.廣東工業(yè)大學(xué)物聯(lián)網(wǎng)智能信息處理與系統(tǒng)集成教育部重點實驗室,廣東 廣州 510006)
0 引言
盲源分離,又稱盲信號分離,是指僅根據(jù)接收的混疊信號(觀測信號)分離或恢復(fù)未知源信號,目的是求得源信號的最佳估計[1-2]。其因強大的分離功能已在通信信號處理[3]、生物醫(yī)學(xué)信號處理(心肺音信號分離等)[4]、圖像處理[5]以及語音信號處理[6-7]等多領(lǐng)域得到了廣泛的應(yīng)用。在實際的信號接收過程中,傳感器的數(shù)目往往小于源信號的數(shù)目(即欠定混疊),導(dǎo)致通道的盲辨識極具挑戰(zhàn)性,特別是在高混響復(fù)雜環(huán)境下,可聽回聲對音質(zhì)有著重要的影響,導(dǎo)致接收信號具有復(fù)雜性,給源信號的分離帶來了巨大的挑戰(zhàn),傳統(tǒng)的盲源分離算法無法徹底解決該類問題。
對人類聽覺系統(tǒng)特性的研究表明,當(dāng)回聲低于由直接聲音引起的掩蔽極限時,將聽不到回聲,這就是人類聽覺系統(tǒng)的時間掩蔽效應(yīng)[8-9]。當(dāng)回聲剛好低于掩蔽極限時人類聽覺系統(tǒng)是聽不見的,人類聽覺系統(tǒng)對那些超過掩蔽極限的回聲非常敏感。在低混響環(huán)境下,可利用空間脈沖響應(yīng)重塑技術(shù)完全消除可聽回聲,而不影響聲音的質(zhì)量。然而,在高混響環(huán)境下,可聽回聲的存在是不可避免的,對此,一些改進的空間脈沖響應(yīng)重塑技術(shù)被提出[10-11]。其中,Jungmann 等[10]結(jié)合聲學(xué)多輸入多輸出信道串?dāng)_消除和空間脈沖響應(yīng)重塑技術(shù)降低了混響的影響。Mertins 等[11]提出的基于凸正則化技術(shù)實現(xiàn)了空間脈沖響應(yīng)重塑和串?dāng)_消除。然而,以上研究主要集中于空間脈沖響應(yīng)重塑技術(shù)本身,而基于該技術(shù)的盲源分離研究尚不多見。鑒于此,本文在盲源分離算法中引入空間脈沖響應(yīng)重塑技術(shù),通過改進該技術(shù)以及設(shè)計新的盲源分離算法,提出面向高混響復(fù)雜環(huán)境的欠定卷積盲源分離算法。
目前,比較流行的盲源分離算法主要利用短時傅里葉變化把時域混疊信號轉(zhuǎn)換到頻域中,根據(jù)信號在頻域上的統(tǒng)計特性[12]、獨立性[13]、非負性[14]、稀疏性[15]等性質(zhì),設(shè)計相應(yīng)的時頻域盲源分離算法。在模型變換過程中,把時域上的卷積混疊變換成頻域上的瞬時線性混疊,減少了時域卷積計算帶來的復(fù)雜性。在低混響混疊環(huán)境下,該模型變換具有較低的近似誤差,由此衍生出一系列欠定卷積盲源分離算法[16-19]。其中,文獻[16-17]基于聯(lián)合矩陣塊對角化方法,實現(xiàn)了卷積混疊信號的盲源分離;文獻[18-19]基于矩陣狀態(tài)協(xié)方差模型,提出了迭代期望最大化算法估計模型參數(shù),通過實時更新優(yōu)化模型參數(shù),再用維納濾波法分離源信號。然而,這類算法收斂速度受限,而且對通道階數(shù)與算法初始化較敏感。
非負矩陣分解是一種機器學(xué)習(xí)算法框架,將非負矩陣分解為2 個低秩非負因子矩陣的乘積[20],在處理卷積混疊盲源分離問題中,通過將源信號的功率譜密度矩陣分解為2 個非負矩陣的乘積,一系列基于非負矩陣分解源模型的盲源分離算法被提出[21-23]。其中,Sawada 等[21]基于非負矩陣分解的低秩源模型,利用多元復(fù)高斯分布的統(tǒng)計模型定義多通道歐幾里得距離和多通道IS(Itakura-Saito)散度,為了最小化這種散度,通過設(shè)計適當(dāng)?shù)妮o助函數(shù),推導(dǎo)出乘法更新形式的優(yōu)化算法;Sekiguchi 等[22]假設(shè)源圖像遵循無約束全秩空間協(xié)方差矩陣的多元復(fù)高斯分布,將空間協(xié)方差矩陣限制為以頻率方式聯(lián)合對角化滿秩矩陣,從而實現(xiàn)了快速多通道非負矩陣分解;Wang 等[23]通過最小體積先驗分布來增強源模型的可識別性,利用最小體積正則化多通道非負矩陣分解,最大化分離源的后驗分布,保證了收斂的穩(wěn)定性。
然而,基于非負矩陣分解設(shè)計的優(yōu)化算法對模型參數(shù)的初始化比較敏感,限制了算法的自適應(yīng)性。另外,時域上的卷積混疊模型通過短時傅里葉變換變換到頻域上的瞬時線性混疊模型是一種近似變換模型,其成立的前提條件是短時傅里葉變換的窗長度遠大于脈沖響應(yīng)的長度,而在高混響環(huán)境下該條件是很難得到滿足的,極易導(dǎo)致較大的模型近似誤差,所以在此變換模型下設(shè)計的算法往往不適用于高混響環(huán)境。對此,文獻[24-25]提出基于卷積傳遞函數(shù)的卷積窄帶近似,該卷積寬帶近似模型能避免以上條件的限制,更精準地近似時域上的卷積模型,適用于高混響混疊情形,但其是卷積計算,容易帶來更高的計算量。
鑒于目前研究現(xiàn)狀,面向高混響環(huán)境的欠定卷積盲源分離問題仍然存在以下難點。
1) 在高混響復(fù)雜環(huán)境下,可聽回聲和混響對音質(zhì)有著重要的影響,導(dǎo)致接收信號具有復(fù)雜性。
2) 缺乏對高混響環(huán)境下欠定卷積混疊信號精確的數(shù)學(xué)建模,導(dǎo)致模型近似誤差增大。
3) 欠定卷積混疊盲源分離實質(zhì)上是一個非線性問題,其求解困難,由于外界環(huán)境的復(fù)雜性,導(dǎo)致傳統(tǒng)盲源分離算法的性能受限。
針對以上問題,本文從空間脈沖響應(yīng)重塑的角度出發(fā),結(jié)合欠定卷積盲源分離研究思路,提出一種面向高混響環(huán)境的欠定卷積盲源分離算法——全局脈沖響應(yīng)欠定盲源分離(GIR-UBSS,global impulse response underdetermined blind source separation)。本文創(chuàng)新點概括如下。
1) 設(shè)計了全局脈沖響應(yīng)網(wǎng)絡(luò),通過優(yōu)化可調(diào)濾波器削弱可聽回聲的影響,提高了信號的質(zhì)量。
2) 構(gòu)建了面向高混響復(fù)雜環(huán)境的時頻域混疊信號數(shù)學(xué)模型,降低了模型近似誤差,對高混響環(huán)境具有較好的自適應(yīng)性。
3) 提出了一種GIR-UBSS 算法,設(shè)計了新模型下參數(shù)的實時更新規(guī)則,實現(xiàn)了源信號的盲分離。理論分析與一系列仿真實驗驗證了GIR-UBSS 算法的有效性與優(yōu)越性。
1 問題描述
對高混響環(huán)境下記錄的混疊信號進行如下數(shù)學(xué)建模。
其中,xj(t)是第j個通道記錄的混疊信號,時間t是連續(xù)的,i= 1,2,…,I是源信號數(shù)目,j= 1,2,…,J是傳感器數(shù)目,a ji(t)是第i個源信號到第j個通道過程中產(chǎn)生的空間脈沖響應(yīng),si(t)是第i個源信號,τ是時延,L是脈沖響應(yīng)的長度,b(t)是噪聲。利用矩陣向量的形式,式(1)可表示為
其中,*是卷積符號,x(t) =[x1(t),…,x J(t)]T,是混疊系統(tǒng)。本文考慮高混響環(huán)境下的欠定卷積混疊盲源分離問題,即I>J為欠定混疊,且空間混響時間逐漸增大導(dǎo)致高混響。盲源分離的目的是僅根據(jù)接收的混疊信號x(t)分離源信號s(t)。
2 本文算法
2.1 全局脈沖響應(yīng)網(wǎng)絡(luò)的設(shè)計
在高混響環(huán)境下,接收到的混疊信號常常伴隨混響回聲,為了消除或削弱可聽回聲的影響,本文設(shè)計一種全局脈沖響應(yīng)網(wǎng)絡(luò),如圖1 所示,該網(wǎng)絡(luò)設(shè)計思路來源于信道串?dāng)_消除和空間脈沖響應(yīng)重塑技術(shù)[10]。
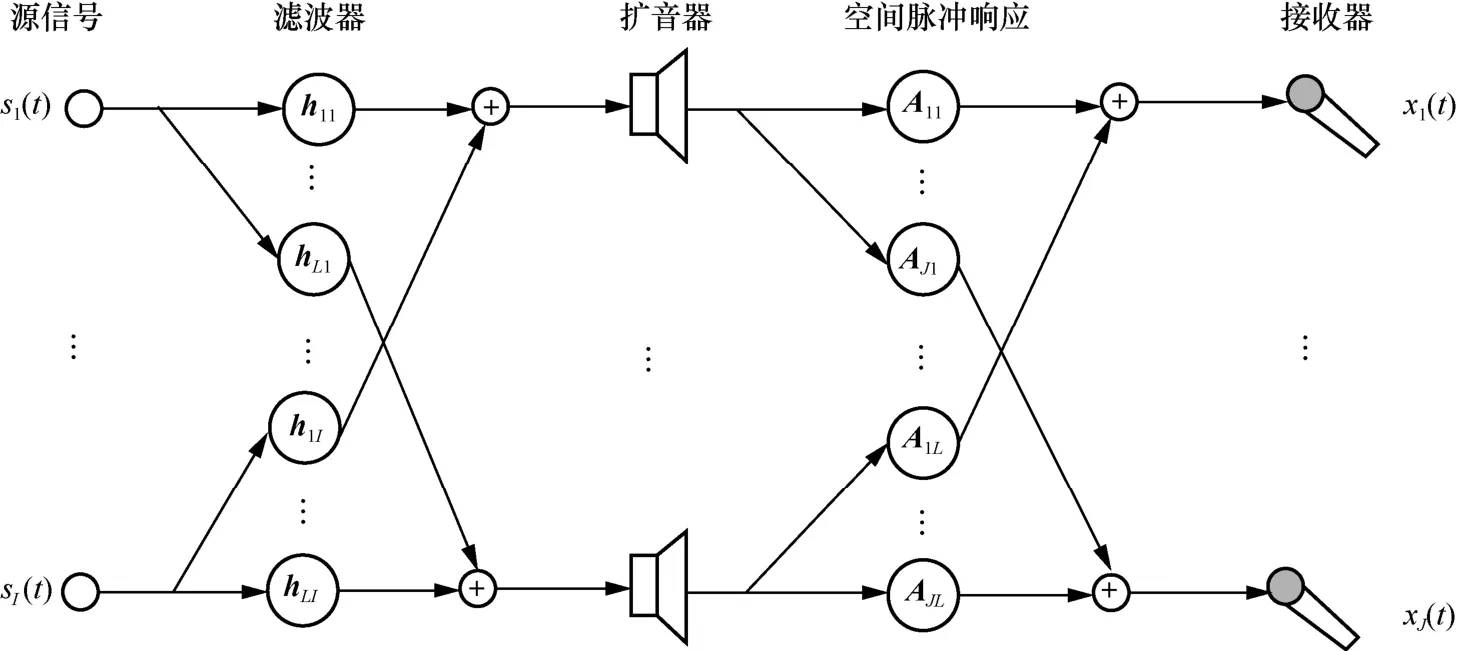
圖1 全局脈沖響應(yīng)網(wǎng)絡(luò)的設(shè)計流程
考慮在接收器前安裝L個擴音器,其中,I個源信號經(jīng)過L個擴音器傳遞到J個接收器,hli是第i個源信號通過第l個擴音器產(chǎn)生的脈沖響應(yīng),其長度為Lh,Ajl是第l個擴音器到達第j個接收器產(chǎn)生的空間脈沖響應(yīng),長度為La,則從第i個源信號到達第j個接收器產(chǎn)生的全局脈沖響應(yīng)可以表示為
其 中,N1=t0fs,N2=αfs,N3=Lg-N1-N2,n=0,…,N3-1;α和β是可調(diào)參數(shù),在設(shè)計濾波器過程中,通過調(diào)節(jié)其值得到不同的窗函數(shù),實現(xiàn)不同的濾波目的。
最小化不期望部分同時最大化期望部分,考慮優(yōu)化問題
其中,pu和pd是可調(diào)的正整數(shù),通過調(diào)節(jié)其值設(shè)計不同范數(shù)的算法,實現(xiàn)不同的脈沖響應(yīng)重塑效果。
利用梯度下降法對式(11)求偏導(dǎo),得到
2.2 欠定卷積盲源分離算法的設(shè)計
2.2.1 模型變換
為解決模型式(2)下的盲源分離問題,傳統(tǒng)的方法利用短時傅里葉變換得到頻域上近似的線性混疊模型,表示為
其中,f=1,…,F是頻點指數(shù),F(xiàn)是短時傅里葉變換的窗長度,n=1,…,N是時間窗指數(shù),和分別是x(t)、s(t)和b(t)通過短時傅里葉變換得到的,噪聲b(t)是模擬現(xiàn)實生活中的真實噪聲,是頻域上的脈沖響應(yīng)混疊矩陣。然而,這種變換成立的前提條件是短時傅里葉變換的窗長度F遠大于脈沖響應(yīng)的長度L,即F≫L。在高混響環(huán)境下,隨著混響時間(RT,reverberation time)的增加,脈沖響應(yīng)的長度L逐漸變大,甚至超過窗長度F,導(dǎo)致線性混疊模型式(16)近似誤差增大,甚至無效。為了避免這種限制,本文設(shè)計全局脈沖響應(yīng)網(wǎng)絡(luò),消除或削弱可聽回聲的影響,縮短脈沖響應(yīng)的長度,降低高混響環(huán)境的影響,建立如下近似模型。
2.2.2 非負矩陣分解模型
假設(shè)[18]
2.2.3 模型參數(shù)的更新規(guī)則
為了更好地分析,通過式(34)和式(35)表示邊際分布和成對聯(lián)合后驗分布,即
因此,通過上述計算g和c的后驗統(tǒng)計量,可最大化對數(shù)似然,表示為
2.2.4 頻域源信號的估計
通過實時更新模型參數(shù),得到頻域上的源信號表達式為
綜上,通過式(46)獲得頻域上的源信號,再利用短時傅里葉逆變換得到時域上的源信號,實現(xiàn)盲源分離。
3 實驗
3.1 實驗參數(shù)設(shè)置與評價準則
為了模擬真實環(huán)境,利用國際上公用的模擬環(huán)境方法[26],創(chuàng)建一個有限脈沖響應(yīng)房間,該房間的維數(shù)是5m×3m×2.5m,固定2 個傳感器,其坐標分別為[3 1 1.6]和[3 1.05 1.6],把源信號放置在3 個位置[2 0.5 1.6]、[2 1 1.6]和[2 1.5 1.6],即3 個源信號兩通道的欠定混疊(I= 2,J=3)。RT 設(shè)置為100~900 ms,值越大說明混響程度越強,通過此模擬環(huán)境產(chǎn)生有混響的欠定混疊信號。在參數(shù)設(shè)置方面,全局脈沖響應(yīng)網(wǎng)絡(luò)中La=Lh=fsRT(fs為信號的采樣頻率),α= 0.05,β=2.0,pu=10,pd=20,iter=1000,μ= 10-6。在非負矩陣分解源模型中,設(shè)置κi= 20;在參數(shù)初始化方面,=I,ufk和vkn利用KL(Kullback-Leibler)散度的非負矩陣分解獲得,且。
為了評價GIR-UBSS 算法的有效性,利用國際公認的評價準則:信號失真比(SDR,source-todistortion ratio)、信號干擾比(SIR,source-tointerference ratio )、信號偽像比(SAR,source-to-artifacts ratio)[27],其值越大,盲源分離性能就越好。因此,利用評價準則SDR、SIR、SAR值的大小衡量盲源分離的好壞。
為了評價GIR-UBSS 算法的優(yōu)越性,對比目前國際上比較流行的幾種盲源分離算法:變分期望最大化(VEM,variational expectation-maximization)算法[19]、卷積近端交替線性化最小化(C-PALM,convolutive proximal alternating linearized minimization)算法[24]、帶正則化的窄帶優(yōu)化(N-Regu,narrowband optimization with regularizatio)算法[24]、全秩空間協(xié)方差模型(FullRankSCM,full-rank spatial covariance model)算法[18]。其中,VEM 算法先利用卡爾曼平滑器估計混疊矩陣和源信號參數(shù),再用維納濾波法分離源信號。C-PALM 算法是一種卷積近似交替線性化極小化方法,通過利用卷積窄帶近似獲得更好的模型近似,減少了卷積核的長度,避免了短時傅里葉變換窗函數(shù)長度的限制。N-Regu 算法是一種經(jīng)典的帶正則化的窄帶優(yōu)化方法,利用了傳統(tǒng)的線性窄帶近似及1-范數(shù)正則化。FullRankSCM 算法利用滿秩空間協(xié)方差模型,是EM 算法中比較成熟的方法之一。以上對比算法是解決欠定卷積混疊盲分離問題中比較流行的算法,通過與這些流行的盲源分離算法進行對比,可以很好地說明GIR-UBSS 算法的優(yōu)越性。同時,所有對比算法中的參數(shù)及模型采用的是與本文實驗相同的設(shè)置,這樣對比更有說服力。
3.2 全局脈沖網(wǎng)絡(luò)去混響效果分析
為了定量描述全局脈沖網(wǎng)絡(luò)實現(xiàn)的去混響效果,將可感知混響量化(nPRQ,perceivable reverberation quantization)度量作為評價準則[11],當(dāng)脈沖響應(yīng)被完全重塑或沒有時間系數(shù)超過時間掩蔽極限時,nPRQ=0,說明混響被完全消除;否則,nPRQ 越大,脈沖響應(yīng)被重塑的效果越差。為了驗證全局脈沖網(wǎng)絡(luò)對不同混響的影響,設(shè)定混響時間RT 為100~900 ms,并與原始脈沖網(wǎng)絡(luò)進行對比,實驗結(jié)果如圖2 所示。相比于原始脈沖網(wǎng)絡(luò),在低混響下,全局脈沖網(wǎng)絡(luò)可以完全消除混響,使nPRQ趨于0;在高混響下,全局脈沖網(wǎng)絡(luò)可以削弱混響的影響,提高信號的質(zhì)量。

圖2 全局脈沖網(wǎng)絡(luò)去混響效果
3.3 仿真實驗1:英文語音信號欠定卷積盲源分離
為了驗證GIR-UBSS 算法的有效性和優(yōu)越性,首選3 組英文語音信號,如表1 所示。數(shù)據(jù)集來源于國際上公開的信號分離評價實驗數(shù)據(jù)。本文創(chuàng)建一個兩通道三語音源的欠定卷積混疊,利用GIR-UBSS 算法進行分離,同時與幾種比較流行的盲源分離算法進行對比,實驗結(jié)果如圖3 所示。從圖3 可知,隨著RT 的增加,算法的分離性能下降,這是由于RT 的增加帶來了混響的復(fù)雜性,導(dǎo)致分離越來越困難,其中,SDR 和SAR 的數(shù)值下降比較明顯,但是SIR 的值比較穩(wěn)定,這是由于本文所設(shè)計的全局脈沖響應(yīng)網(wǎng)絡(luò)可以很好地減弱RT 的影響,從而得到穩(wěn)定的SIR。

表1 仿真實驗1:3 組英文語音
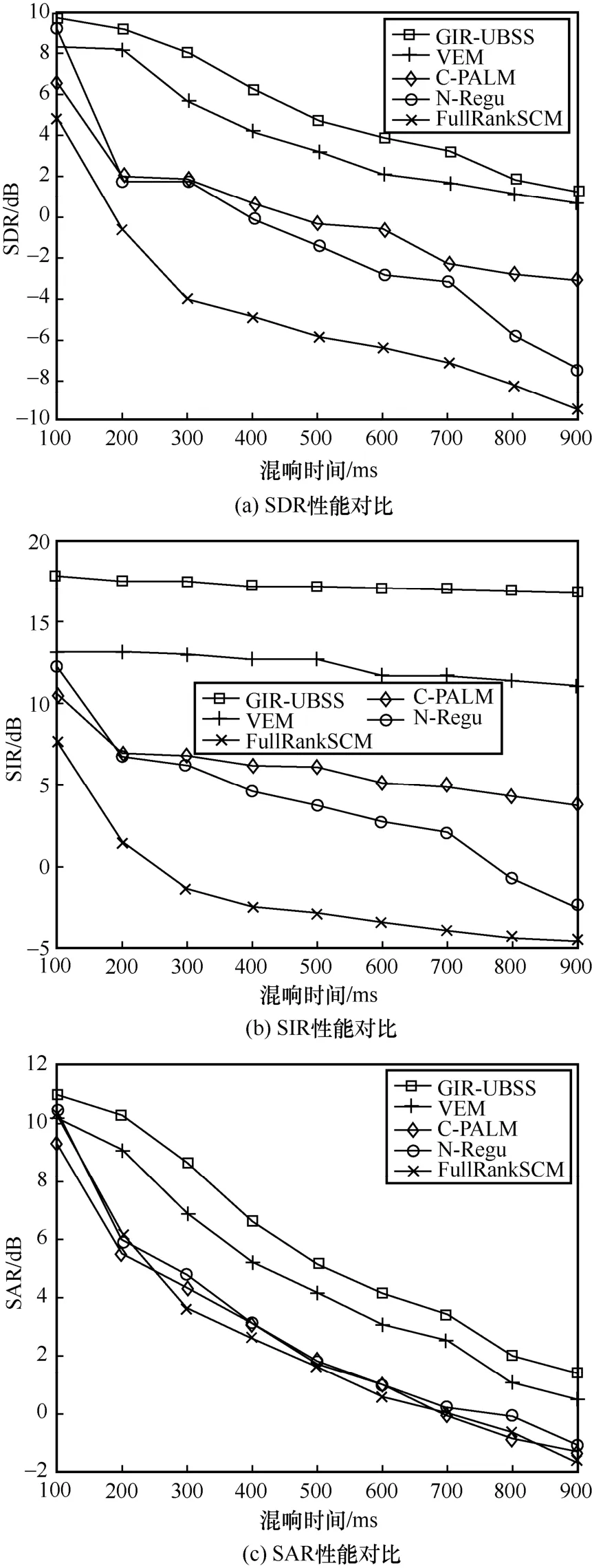
圖3 英文語音信號欠定卷積盲源分離性能對比
在高混響環(huán)境下,對比算法分離性能下降嚴重,甚至失效,而GIR-UBSS 算法依然可獲得較好的分離結(jié)果。與對比算法中最好的分離結(jié)果相比,GIR-UBSS 算法得到的SDR、SIR 和SAR 值分別提高了約1 dB、5 dB 和1 dB,該實驗驗證了GIR-UBSS算法在高混響環(huán)境下分離欠定卷積語音混疊信號的有效性和優(yōu)越性。
另外,為了從視覺的角度解析英文語音混疊信號分離情況,可視化混響時間為300 ms 下的原始英文語音混疊信號波形以及分離后的英文語音信號波形,如圖4 所示。
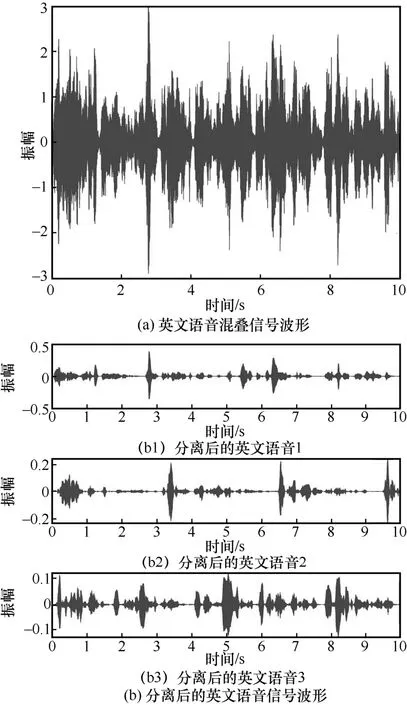
圖4 英文語音混疊信號波形以及分離后的英文語音信號波形
3.4 仿真實驗2:音樂信號欠定卷積盲源分離
為了驗證GIR-UBSS 算法對音樂混疊信號的有效性和優(yōu)越性,測試3 組音樂欠定卷積混疊信號,選取的源信號如表2 所示,該音樂信號包括吉他聲、人聲和鼓聲,全時長為25 s,采樣頻率為44.1 kHz,為了減少分離所需的時間,本文實驗將信號截斷為10 s,下采樣至16 kHz,保持與實驗1 的一致性,盲源分離結(jié)果如圖5 所示。

表2 仿真實驗2:3 組音樂信號

圖5 音樂信號欠定卷積盲源分離性能對比
從圖5 可知,隨著RT 的增大,算法的分離性能與預(yù)期基本一致。與對比算法中最好的分離結(jié)果相比,GIR-UBSS 算法得到的SDR、SIR、SAR 值分別提高了約6 dB、7 dB 和6 dB。該實驗驗證了GIR-UBSS 算法在高混響環(huán)境下分離欠定卷積音樂混疊信號的有效性和優(yōu)越性。
與仿真實驗1 的結(jié)果對比可發(fā)現(xiàn),GIR-UBSS算法在分離音樂混疊信號表現(xiàn)出更好的優(yōu)越性。這是由于本文利用了非負矩陣分解源模型,相比于語音源,音樂源可以被較小數(shù)目的源成分表示,更適用于非負矩陣分解模型,從而獲得更好的分離結(jié)果。
為了從視覺的角度解析音樂混疊信號分離情況,可視化300 ms 下的原始音樂混疊信號波形以及分離后的音樂信號波形,如圖6 所示。
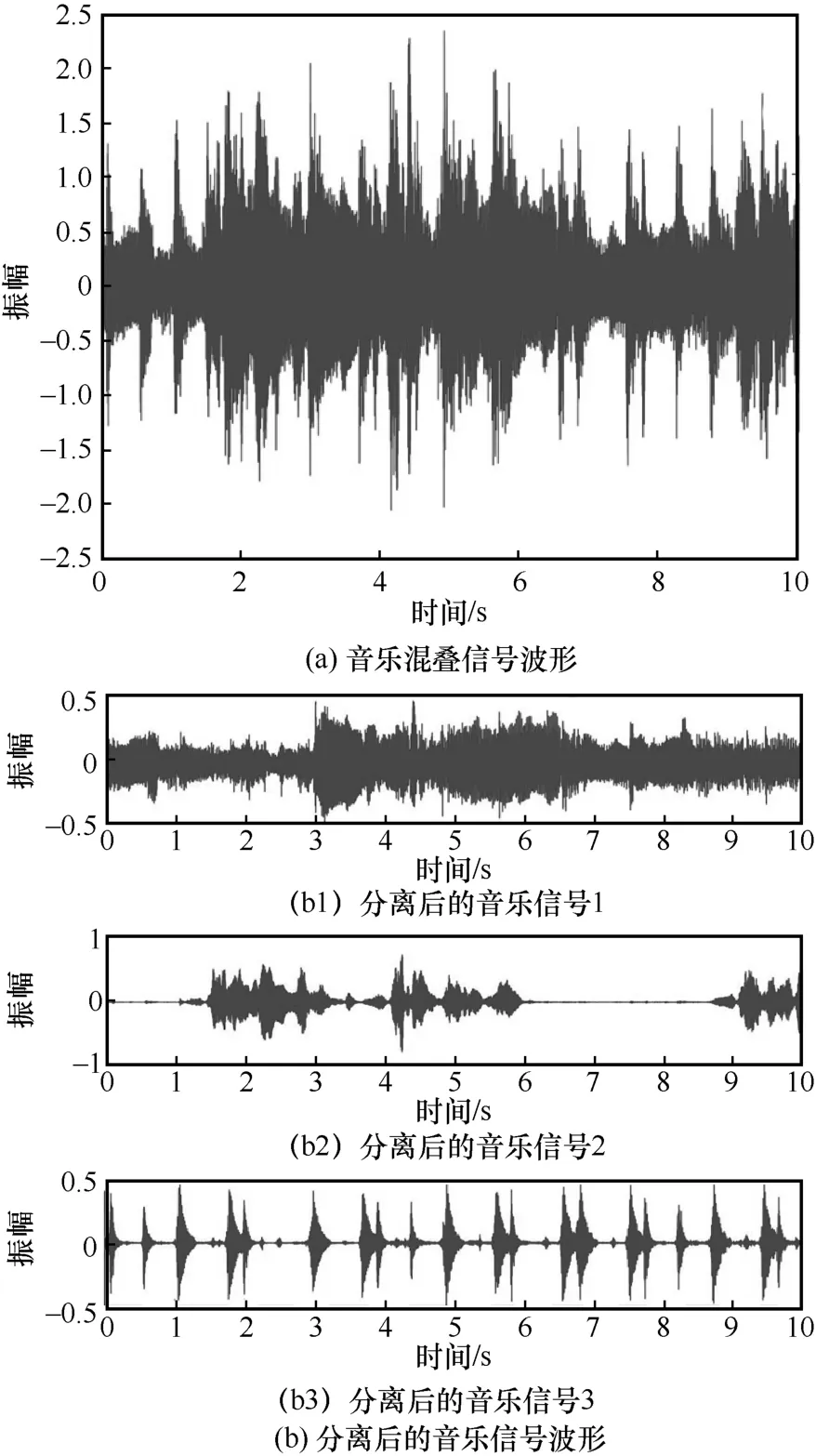
圖6 音樂混疊信號波形以及分離后的音樂信號波形
3.5 仿真實驗3:中文語音信號欠定卷積盲源分離
為了驗證GIR-UBSS 算法對中文語音混疊信號的有效性和優(yōu)越性,測試3 組中文語音混疊信號,數(shù)據(jù)集來自國內(nèi)公共中文語音數(shù)據(jù)集。選取3 組語音信號,如表3 所示,盲源分離結(jié)果如圖7 所示。與對比算法中最好的分離結(jié)果相比,GIR-UBSS 算法得到的SDR、SIR、SAR 值分別提高了約1 dB、5 dB 和1 dB。驗證了GIR-UBSS 算法對分離中文語音欠定卷積混疊信號仍然具有較好的有效性和優(yōu)越性。

表3 仿真實驗3:3 組中文語音
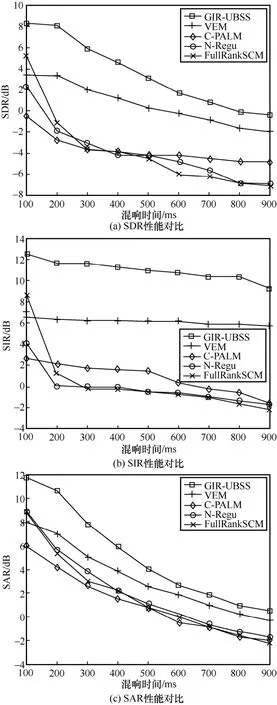
圖7 中文語音信號欠定卷積盲源分離性能對比
另外,為了從視覺的角度解析中文語音混疊信號分離情況,可視化混響時間為300 ms 下的原始中文語音混疊信號波形以及分離后的中文語音信號波形如圖8 所示。
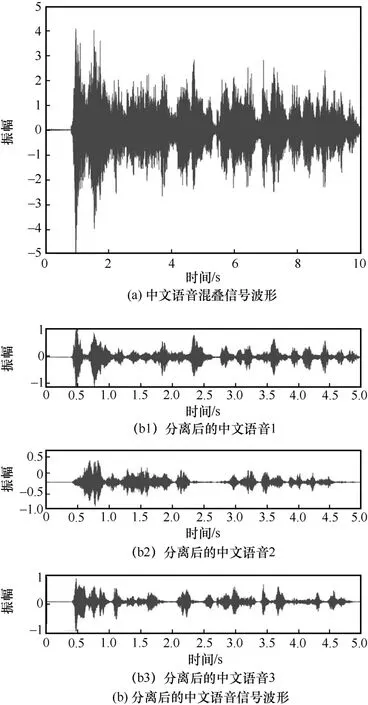
圖8 中文語音混疊信號波形以及分離后的中文語音信號波形
3.6 算法對真實噪聲的穩(wěn)健性分析
為了驗證GIR-UBSS 算法對真實噪聲的穩(wěn)健性,現(xiàn)實生活中遇到的噪聲場通常可以近似為球形或圓柱形噪聲場,如時間相關(guān)噪聲、由相互獨立的語音片段混合而成的巴布語音或工廠噪聲,以及室外測量經(jīng)常受到各種聲源(如交通、自然環(huán)境聲音等)的干擾。本文實驗測試3 種真實噪聲:由球形產(chǎn)生的各向同性噪聲(isotropic noise)、由相互獨立的語音片段混合而成的巴布語音噪聲(babble noise)以及風(fēng)噪聲(wind noise)。然后分別把這3 種噪聲加入仿真實驗1 中的混疊語音信號中構(gòu)成含噪聲的混疊信號,利用GIR-UBSS 算法對混疊信號進行分離,同時對比無噪聲(without noise)下的盲源分離,實驗結(jié)果如圖9 所示。從圖9可知,加入不同噪聲以后獲得的盲源分離結(jié)果與無噪聲下得到的結(jié)果相似,驗證了GIR-UBSS 算法對真實噪聲具有很好的穩(wěn)健性。

圖9 含有真實噪聲的盲源分離性能對比
4 結(jié)束語
現(xiàn)實生活中,接收的混疊信號往往伴隨高混響等不確定因素,如何消除或削弱高混響的影響,提高盲源分離性能,已經(jīng)成為信號處理中極具挑戰(zhàn)性和現(xiàn)實意義的課題。為此,本文提出一種面向高混響復(fù)雜環(huán)境的欠定卷積盲源分離算法,通過設(shè)計全局脈沖響應(yīng)網(wǎng)絡(luò),減少脈沖響應(yīng)的長度,削弱可聽混響回聲的影響。進而構(gòu)建高混響環(huán)境的時頻域混疊信號數(shù)學(xué)模型,設(shè)計新模型下的參數(shù)更新規(guī)則,實現(xiàn)源信號的盲分離。理論分析表明,在新的實時模型更新規(guī)則下,可得到頻域上的源信號。實驗驗證了所提GIR-UBSS 算法對分離中英文語音混疊信號、音樂混疊信號具有很好的有效性。另外,通過與國際上比較流行的盲源分離算法對比,證實了GIR-UBSS 算法的優(yōu)越性,以及對真實噪聲具有良好的穩(wěn)健性。